Onboarding was hurting adoption
2–3 hours → ~30 minutes
Worst-case time to first operational insight
AIOps surfaces operational, health, and security insights across enterprise firewall infrastructure. In beta, onboarding behaved as an all-or-nothing gate. Customers waited hours before they could see reliable value from a new, largely untested product—AIOps (we were about four to five months into GA at the time).
Customers could not tell whether the product was making progress, blocked, or silently failing. The initial onboarding process was completely opaque. That had been acceptable in beta but was prioritised for redesign on the basis of improving time to first insight.
Our main principle for the project was our insight that customers did not need full platform completion. They needed reliable insight as early as possible.
Prove value as fast as possible
We decided to move the onboarding strategy from "complete first, then reveal" to "unlock value as soon as possible.”
The new model would ensure that features that onboarded fast could immediately start providing value. This immediately dropped the time to first insights which was the north star metric for the project.
This allowed us to generate insights from the core platform, while the supporting platforms could onboard and provision at their pace.
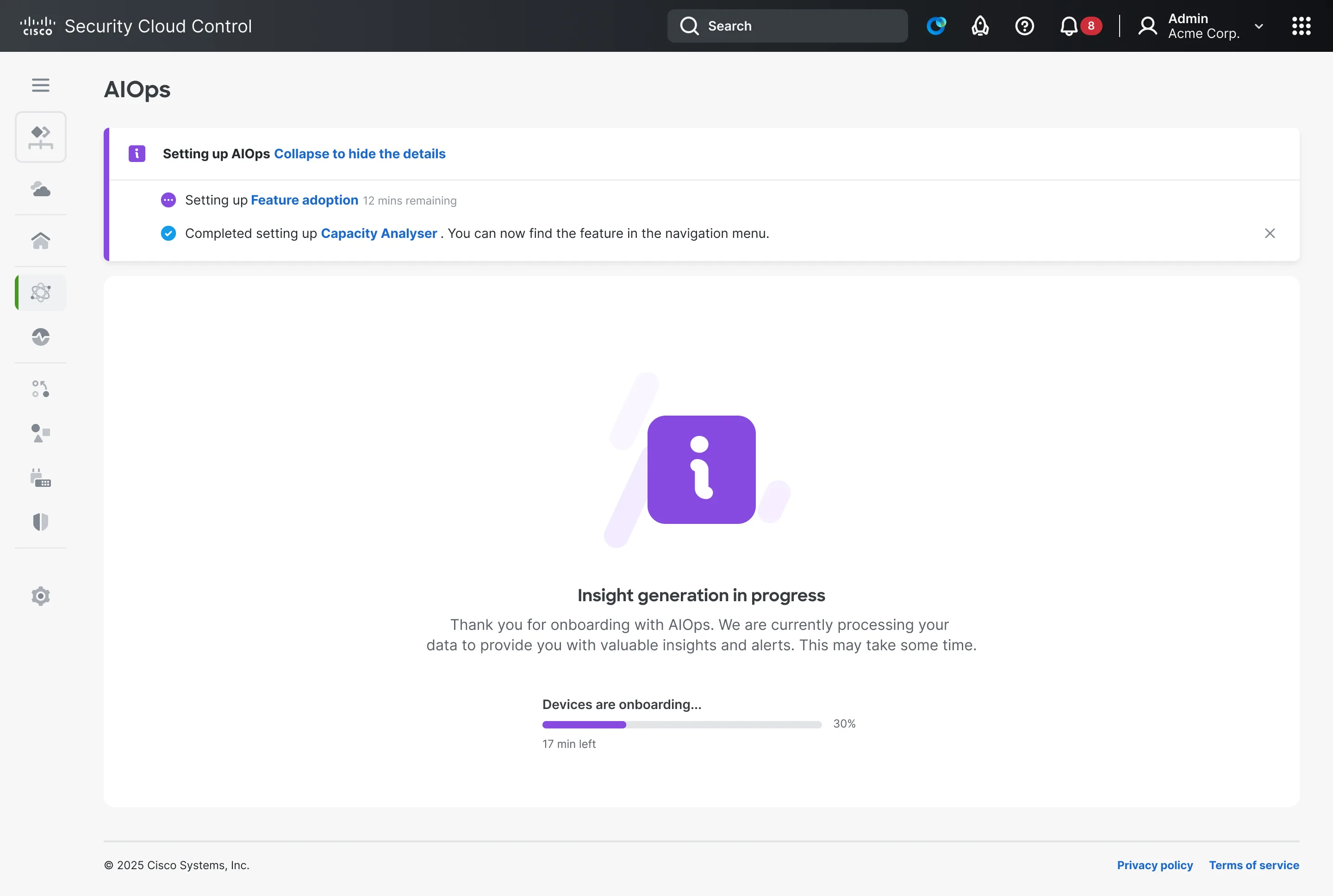
Two setups in effect: main onboarding completes faster than the others.
Providing visibility to ensure trust
Our core delivery fails if users cannot understand what is happening inside the onboarding. We wanted to ensure the users understood where they stood in regard to all features.
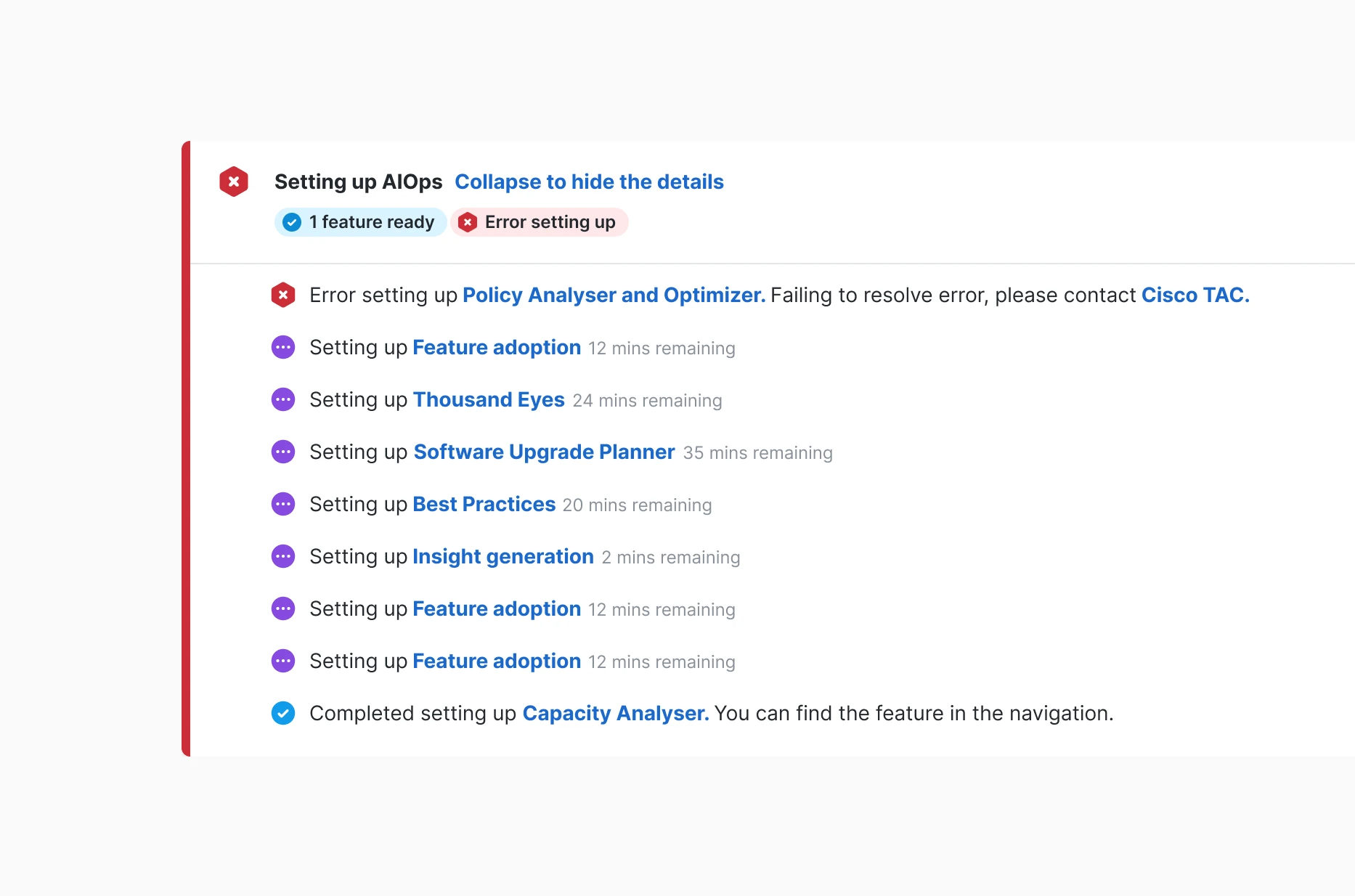
Users always know what is ready, what is waiting, and what requires action.
The decision was to use a persistent notification bar to signal the progress. This was done to ensure that users could access the core platform faster, while still being able to review the progress in the other features.
One contentious choice was the lack of dismissibility. Allowing users to hide the notifications reduced visual noise, but it also removed the only stable status surface users relied on.
Transparency and ease of engineering effort were prioritised over cleanliness, so onboarding state stayed visible until success or intervention.


Detail view showing readiness, in-progress states, and failure signals in one place.
The notification banner animating through onboarding states.
Some micro-interactions designed to communicate the status of progress
Handling developer experience for recovery
As deployments expanded across hybrid and on-prem environments, full restart patterns became expensive for operators. They could only see one failure at a time and had to re-run the flow to understand where breaks were happening. This was a major use case for AIOps API users as well as internal Cisco engineers.
So as we shifted recovery towards the new model, we allowed users access to error logs to debug their environment issues.
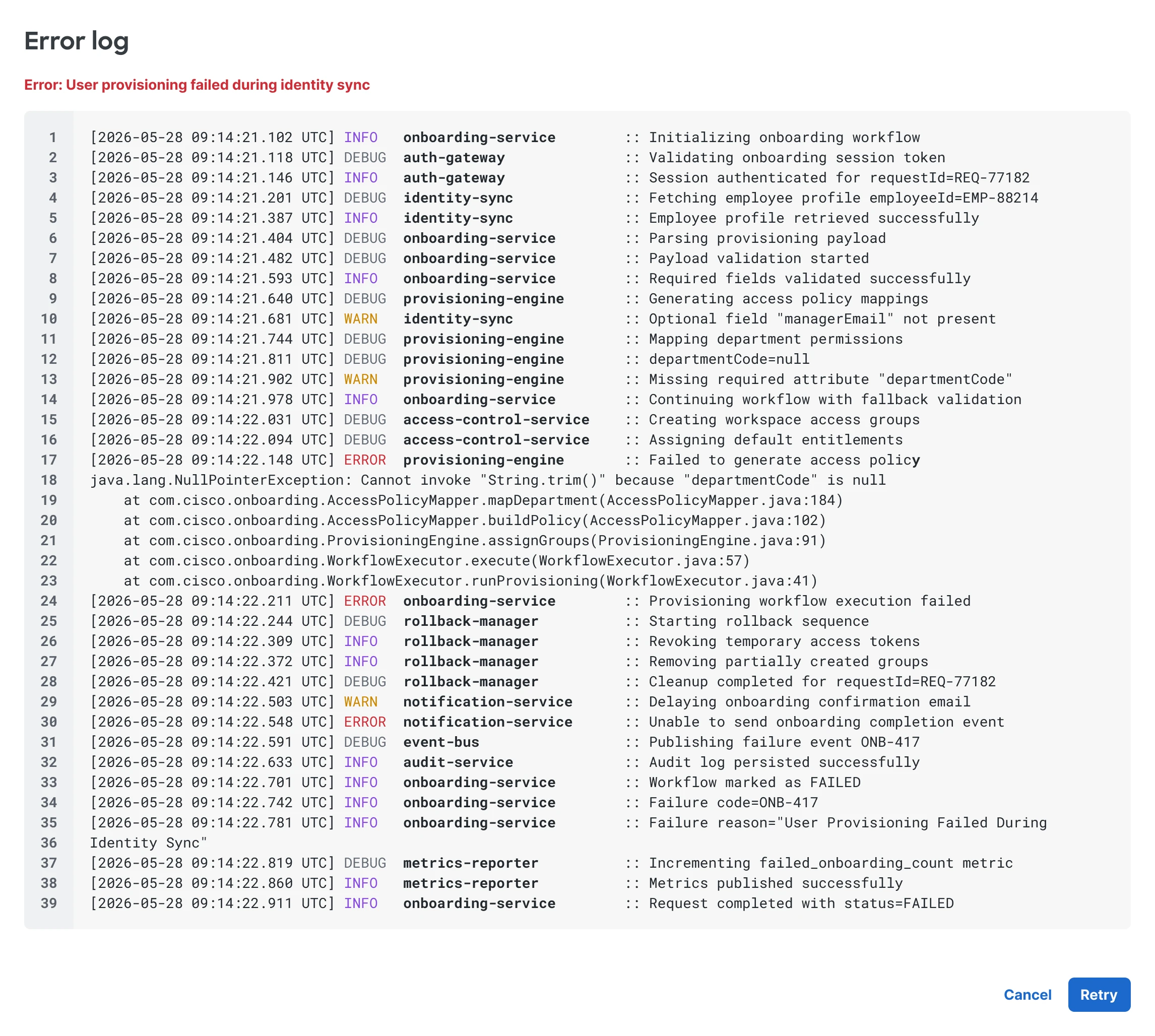
Surfacing error logs from failures; data is purely representational.
How transparent should we be?
AIOps onboarding had to support:
- greenfield deployments
- legacy firewall infrastructure
- restricted on-premise environments
- multi-device onboarding workflows
With so many surfaces, we ran into multiple users from research asking for different granularity in the information they could view.
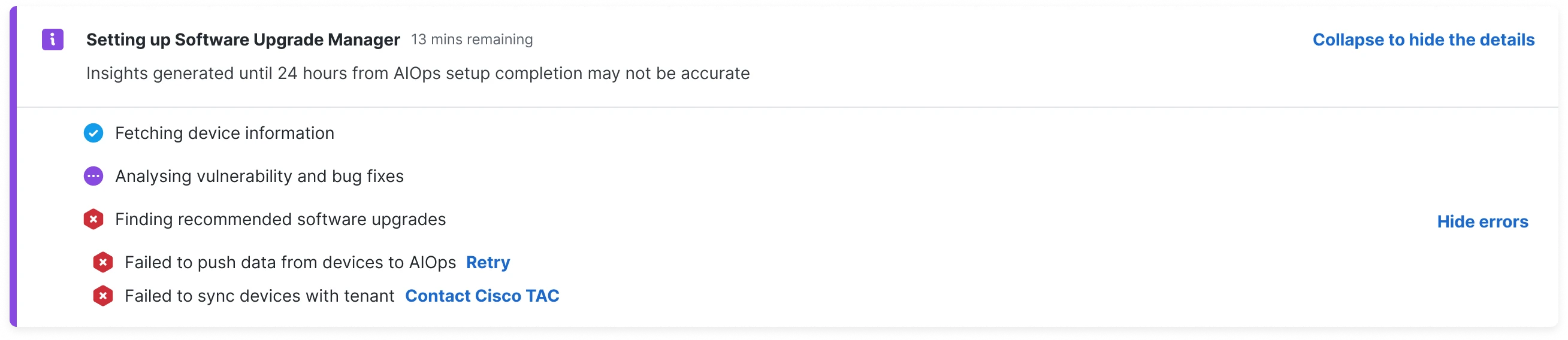
An early direction focused on feature-specific progress indications. This level of granularity was dropped later based on engineering decisions. We did provide log data, but the effort to build per-feature onboarding groups was considered low return on investment.
However, we did decide to make compatibility explicit from the start:
- supported capabilities
- unavailable integrations
- infrastructure-specific limitations
would all be surfaced before we onboarded. This feature listing was added so users would know how the deployment would function and how long it would take for AIOps to start functioning.
Iteration sequence that established the final progressive unlock model.
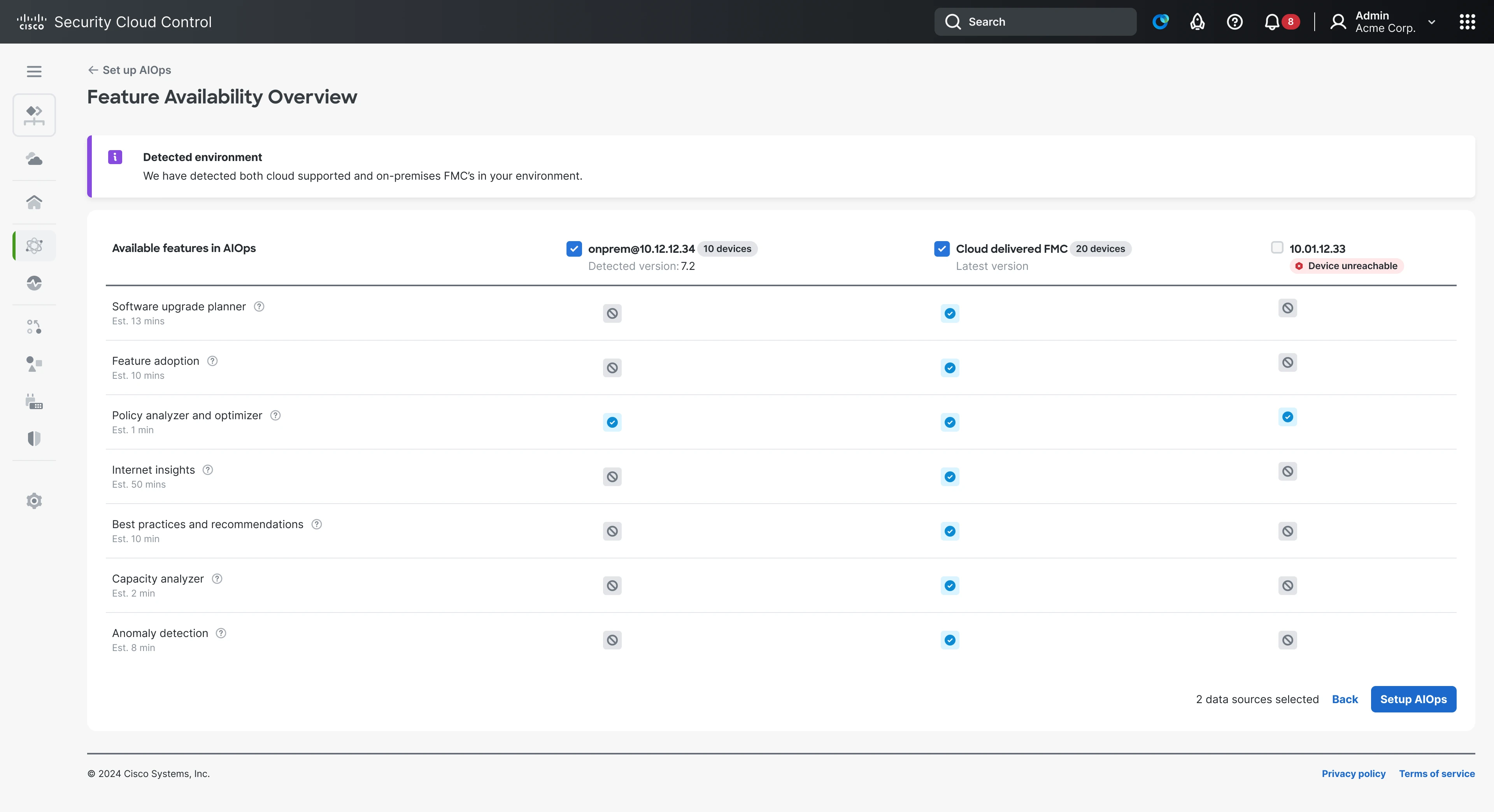
Explicit capability states for each firewall across versions and deployment conditions.
Key decisions and tradeoffs we made
- Progressive value over full completion: surfaced reliable capabilities early instead of waiting for perfect readiness, to minimise time to first insight as required.
- Transparency over visual minimalism: kept onboarding status persistent even when it added UI weight. Giving users visibility into status ensured there was no confusion about why certain insights were pending. We used existing design system patterns to speed up development as well.
- Isolated recovery over restart flows: reduced rework and protected partially completed setup. This was mainly for internal teams as they required visibility at one point into provisioning failures.
- Capability clarity over hidden complexity: exposed unsupported states early to reduce downstream surprises. Older versions incompatible with new capabilities had been a major adoption bottleneck for AIOps, so we had to ensure customer trust was never eroded.